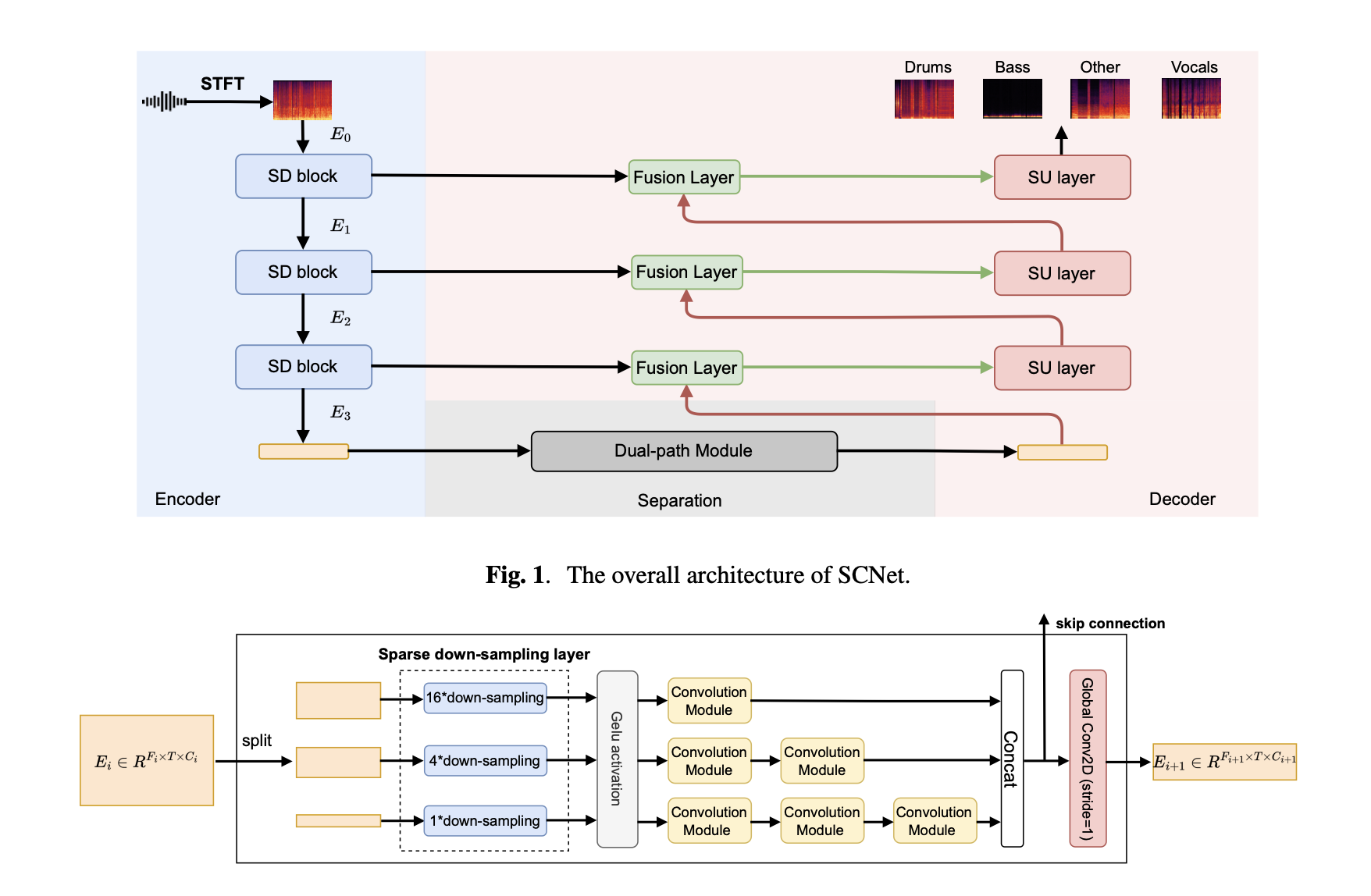
SCNet: Sparse Compression Network for Music Source Separation
Deep learning-based methods have made significant achievements in music source separation. However, obtaining good results while maintaining a low model complexity remains challenging in super wide-band music source separation. Previous works either overlook the differences in subbands or inadequately address the problem of information loss when generating subband features. In this paper, we propose SCNet, a novel frequency-domain network to explicitly split the spectrogram of the mixture into several subbands and introduce a sparsity-based encoder to model different frequency bands. We use a higher compression ratio on subbands with less information to improve the information density and focus on modeling subbands with more information. In this way, the separation performance can be significantly improved using lower computational consumption. Experiment results show that the proposed model achieves a signal to distortion ratio (SDR) of 9.0 dB on the MUSDB18-HQ dataset without using extra data, which outperforms state-of-the-art methods. Specifically, SCNet's CPU inference time is only 48% of HT Demucs, one of the previous state-of-the-art models.
PDF AbstractCode

Tasks

Datasets
 MUSDB18-HQ
MUSDB18-HQ

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Music Source Separation | MUSDB18-HQ | SCNet-large | SDR (drums) | 10.98 | # 2 | |
| SDR (bass) | 9.49 | # 5 | ||||
| SDR (others) | 7.44 | # 3 | ||||
| SDR (vocals) | 10.86 | # 2 | ||||
| SDR (avg) | 9.69 | # 3 | ||||
| Music Source Separation | MUSDB18-HQ | SCNet | SDR (drums) | 10.51 | # 4 | |
| SDR (bass) | 8.82 | # 6 | ||||
| SDR (others) | 6.76 | # 7 | ||||
| SDR (vocals) | 9.89 | # 7 | ||||
| SDR (avg) | 9.00 | # 5 |
